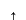The story of this blogpost goes back to July 2017, Santa Fe. I was a student at SFI Complex Systems Summer School, where I had a series of very interesting lectures on chaotic systems and nonlinear time series analysis. During one of the lectures, we had plots of two different time series, one coming from a chaotic system without any noise, and one being purely noise. The question was, of course, which one is which. I tried to demonstrate the same for you just below. One of the time series is the downsampling of the Mackey-Glass equation which shows a chaotic behaviour, and the other is simply white noise. Hard to say just by looking at it. You can see the underlying dynamics of the Mackey-Glass equation when you move the cursor to the chaotic plot.



There are many studies concerned with this fundamental issue of distinguishing chaos from noise, which can be a real challenge. Both chaotic and random signals exhibit irregular temporal fluctuations, both have a fast-decaying auto-correlation function, and both are hard to forecast. But the nature of their dynamics are quite different : chaos is deterministic, noise is not [1]. That's the reason why the question of chaos versus noise is so attractive : low-dimensional nonlinear determinism may allow short-term predictability [2]. In a deterministic system, short-term futures of two almost-identical states should be similar, whereas in a pure noise process, that is improbable [1].
This idea of "future of my peers is my future" was first proposed by Lorenz in 1969 to predict the atmosphere [3]. He introduced the "Lorenz Method of Analogues", which searches the known state-space trajectory (in this case the state variables are temperature, pressure, distribution of wind, water vapor, etc.) for the nearest neighbor of a given state, and takes that neighbor’s forward path as the forecast. Essentially, it is a nearest-neighbor prediction.
Lorenz used all the variables, i.e., the full system state space - at least the full one he could think of. Say he could only measure temperature, but he also knew that the state space has a bigger dimension - more variables - than only one. This is generally the case when we observe natural phenomena. Governing equations and the state variables are rarely known, and have access to only a few scalar measurements observed from the system. What can be done with that? It simply depends on how much information is contained in the dynamics of the variable "temperature". It can be the case that one observed variable contains all the dynamical information of the system, and such systems are called inseparable.
The concept of inseparability deserves a bit of attention, also because of its role in quantum mechanics (It is indeed what Einstein called "spukhaft Fernwirkung" or "spooky action at a distance"). In terms of dynamical systems, inseparability means that the variables of a system cannot be computed separately. As an example, say you have a an ODE system in the following form \begin{align} \frac{dx}{dy} = g(x)h(y). \end{align} As long as \(h(y) \neq 0\), terms can be rearranged such that \begin{align} \frac{1}{h(y)}dy - g(x)dx = 0. \end{align} One can compute the two integrals \(\int \frac{1}{h(y)}dy\) and \(\int g(x)dx\) separately, and solve the equation. Good old separation of variables. On the other hand, imagine you have the following form of ODEs \begin{align} \frac{dx}{dy} = g(x)+yh(x). \end{align} This simply cannot be solved by using separation of variables, since you will have \(dx\) terms associated with \(y\), and vice versa. Hence the system is inseparable. This is actually useful for prediction purposes, because it tells us that if the atmosphere is an inseparable nonlinear system, then one of the observed variables - in this case temperature - can contain all the dynamical information about the atmosphere itself. One cannot compute the atmosphere without the temperature, and the temperature without the atmosphere.
The next question is how to squeeze out this information from the scalar time series we observed : How to reconstruct the state vector of the dynamical system from a single observed variable.
Solution to this problem was first proposed by Norman Packard and colleagues in 1979, and later was formalized by Floris Takens. Packard asked the same question in the context of fluid dynamics : How can we discern the nature of the strange attractor underlying turbulence from observing the actual fluid flow? [4]
The heuristic idea behind the reconstruction method is the following : to specify the state of an \(m\) dimensional system at a given time, you need \(m\) independent quantities. As an example, say you have a 3-dimensional system \begin{align} \mathbf{s}_{t} = \Big(x_{t},\,y_{t},\,z_{t}\Big), \end{align} and you aim to reconstruct an equivalent of \(\mathbf{s}_{t}\) (this means certain characteristics of \(\mathbf{s}_{t}\) should remain intact) by just observing \begin{align} x_{t} = x(\omega),\,\,\omega\in[0,t]. \end{align} Since you only have \(x(t)\), there is not much to do but try to generate several different scalar series from it. Simplest way to do it is to delay the same signal in time [5], and generate 3 different time series such that the reconstructed state of the system is defined as \begin{align} \mathbf{x}_{t} = \Big(x_{t},\,x_{t-\tau},\,x_{t-2\tau}\Big). \end{align} Here, the term independent in "\(m\) dimensional system \(\rightarrow\) \(m\) independent quantities" relation gains some practical meaning. Since you are delaying the very same signal, how can you minimize the redundancy between the delayed signals while having them still casually related (not completely irrelevant)? At the end, you don't want all dimensions to be the same, but you also don't want them to be so irrelevant such that there is no meaning in putting them together.
As you can imagine, there has been many techniques proposed to find the optimal delay time \(\tau\) using different measures (correlation, mutual information, etc.). I will not go into the details of that discussion, and simply move on assuming that we have a \(\tau\) that is good enough.
Back to the reconstruction problem. What Packard and colleagues conjectured in [4] was the following
1) One-to-one and onto (every point on \(\mathbf{s}_{t}\) paired with exactly one point on \(\mathbf{x}_{t}\) and vice versa).
2) Invertible.
3) Differentiable with also its inverse being differentiable (smooth).
This operation of mapping the scalar time series on an \(m\) dimensional space is called embedding, with embedding dimension being \(m\).
Although the word "diffeomorphism" sounds a bit scary, it is actually quite common in image processing. As an example, a fish eye filter can be thought as a mapping from a disc to a sphere, is a diffeomorphism. You can see a cute example [6] below :)

Say a dynamical system generates a trajectory in a \(D\) dimensional manifold \(\Gamma\). For discrete time, the dynamical system is defined by the \(D\)-dimensional map \(\mathbf{F}\,:\,\Gamma \mapsto\,\Gamma\) as
\begin{align}
\mathbf{s}_{n+1} = \mathbf{F}(\mathbf{s}_{n}),\,\,\, n\in \mathbb{N},
\end{align}
where \(\mathbf{s}_{n} \in \Gamma \) is the state vector at time step \(n\). The observed scalar time series \(\{x_{n}\}_{n=1}^{N}\) of length \(N\) is the projection of the trajectory \(\{\mathbf{s}_{n}\}_{n=1}^{N}\) given by a measurement function \(h\,:\,\Gamma \mapsto \mathbb{R}\), as \(x_{n} = h(\mathbf{s}_{n})\).
According to Takens' Embedding Theorem, a trajectory formed by the time-delayed components from the time series \(x_{n}\) as \begin{align} \mathbf{x}_{n} = \Big({x}_{n},\,{x}_{n-\tau},\dots,\,{x}_{n-(m-1)\tau} \Big) \end{align} is an one-to-one mapping of the original trajectory of \(\mathbf{s}_{n}\) provided that m is large enough. Given that the dynamical system evolves to an attractor \(A \subset \Gamma \), the reconstructed attractor \(\overset{\sim}{A}\) through the use of time-delay vectors is topologically equivalent to \(A\). The embedding process can be visualized with the following graph [10] \[ \begin{array}{ccc} \mathbf{s}_{n} \in A \subset \Gamma & \xmapsto[]{\mathbf{F}} & \mathbf{s}_{n+1} \in A \subset \Gamma \\ \downarrow h & &\downarrow h \\ x_{n} \in \mathbb{R} & & x_{n+1} \in \mathbb{R} \\ \downarrow e & &\downarrow e \\ \mathbf{x}_{n} \in \overset{\sim}{A} \subset \mathbb{R}^{m} & \xmapsto[]{\mathbf{G}} & \mathbf{x}_{n+1} \in \overset{\sim}{A} \subset \mathbb{R}^{m} \end{array} \] where \(e\) is the embedding procedure creating the delay vectors, and \(G\) is the reconstructed dynamical system on \(\overset{\sim}{A}\). \(G\) preserves properties of the unknown \(F\) on the unknown attractor \(A\) that do not change under smooth coordinate transformations.
Let's check if that really works. Below you see a reconstruction of the Lorenz System using time-delay vectors of each dimension \(x_{t}\), \(y_{t}\), and \(z_{t}\). The colored points have the same index \(n\) to demonstrate the one-to-one and onto mapping property of the embedding.

Going back to the "large enough \(m\)" question : basically what we are doing by this embedding is projecting the time-delayed versions of the original time series on different axis of a higher dimensional space. Our aim is to preserve the properties of \(F\) in the reconstructed \(G\). Apart from the topological properties specific to \(F\), what is the fundamental property of any deterministic dynamical system? Trajectories cannot cross. A deterministic dynamical system's time evolution is determined entirely by its current location in the phase space. Meaning that if you're a given point in phase space, the next place you go is uniquely determined. Two trajectories that meet at the same point in the phase space are completely physically identical at that point, so they can't evolve in two different ways from identical initial conditions.
This gives us the condition of what the minimum embedding dimension should be : no crossing of trajectories. How can we check that? Kennel and colleagues proposed a practical way to do it in [11], which they called "The Method of False Neighbors". I really like the distinction he makes between a mathematician and physicist in the context of this problem. He says,
What should be the practical reasoning for picking an embedding dimension then? Recall the "Lorenz Method of Analogues", which said the future of the nearest neighbors is the future of the current state. If neighbors of a current state depends on the embedding dimension, then it is a problem. For the idea of nearest-neighbor prediction to work, any dimension \(m \geq m_{E}\) should give similar neighbors. Otherwise, we are viewing the attractor in a too small embedding space.
A quick visual demonstration can be useful. In the figure below, you see the embedding of the Hénon map for \(m=2\) (top) and \(m=1\) (bottom). For \(m=1\), all three points - red, blue, and the green one - seem like they are neighbors. When the embedding dimension is increased by one, \(m=2\), then we see that the red point is actually a false neighbor. You can try to embed the system also for \(m=3\), and see that the blue and the green points stay neighbors although the red one is still false. We conclude that in this case \(m=2\) is sufficient to unfold the attractor.

This is the basic idea of "The Method of False Neighbors". Of course, a visual demonstration like above is not possible in most cases, so one needs to come up with an algorithmic way to find \(m\). Similar to the problem of determining the optimal \(\tau\), determining the minimum \(m\) is yet another question. Again, I will assume that we can find the minimum \(m\) using algorithms proposed in the literature, and skip that discussion for now. Using all this information, we can finally move to the problem of predicting a scalar time series.
The problem is the following : We observed the scalar time series \(x_{n} = \Big(x[n],x[n-1],\dots,x[1]\Big)\), and we want to predict the next value of it in the future, \(x[n+1]\). It is likely that the data is coming from a higher dimensional system (observing the results of a natural complex phenomena, for example). We ignore any kind of noise - both system and observational - for the time being.
We can use the method of analogues proposed by Lorenz, but we don't have state vectors, we have scalars. That's where the method of analogues meet Takens' theorem. We can embed the time series, then find neighbors, and do the prediction. In other words, what we want to do is the green path in the diagram below.

Thanks to Takens, we know that the blue path is possible (recall all the properties about embedding being one-to-one and invertible, etc.). But we don't need to find \(G\) and invert the embedding, because other dimensions are also coming from the same scalar time series anyway. Predicting \(x_{n+1} = \Big(x[n+1],x[n],\dots,x[2]\Big)\) is not necessary for the sake of predicting \(x[n+1]\), because we already have the rest of the signal : \(\Big(x[n],\dots,x[2]\Big)\). So instead of taking the detour, we will take the red path, and apply the method of analogues when taking the turn.
Mathematically speaking, we will try to find the map \(g^{T} : \mathbb{R}^{m} \rightarrow \mathbb{R}\) such that \begin{align} x[n+T] &= g^{T}\Big(\mathbf{x}_{n}\Big), \\ &= g^{T}\Big({x}_{n},\,{x}_{n-\tau},\dots,\,{x}_{n-(m-1)\tau} \Big), \end{align} for \(T=1\), where \(g^{T}\) is assumed to be in the form of \begin{align} x[n+T] = \alpha_{0} + \sum_{k=1}^{m} \alpha_{k}x[n-(k-1)\tau], \end{align} which is simply an autoregressive model.
To sum it up, forecasting works as follows,
1) Find the nearest neighbors (NNs) of the embedded state \(x_{n}\).
2) Estimate the regression coefficients by using the future values of the NNs, which are already in the scalar time series (do some linear regression to get the \(\alpha_{k}\) values).
3) Use these coefficients for \(g^{T}(\mathbf{x}_{n})\) to forecast the first element of the future state \(x[n+T]\).
The beautiful part is that by using a sufficiently large embedding dimension, we can be sure that the neighbors we are using for the method of analogues are true neighbors. That is why the sufficient embedding dimension was a practical concern for Kennel.
The pseudocode of the whole algorithm proposed in [12] is below, and the link to the GitHub project is at the end of the post.
I love plotting so here we go :) Below, you see the demonstration of the forecasting algorithm on the reconstructed Lorenz attractor. The black dot is the current state of the system, \(x_{t}\), embedded by using time-delay vectors where \(m=3\). The gray point is the real value of \(x_{t+T}\), current state \(T\) steps ahead in the future. The greenish / yellowish points are the nearest neighbors of the black dot, which are used for the approximation of the autoregressive model coefficients (color gets lighter as the distance to \(x_{t}\) gets bigger). Finally, the red circle is the predicted value \(\hat{x}_{t+T}\), projected back on the reconstructed attractor.
 If we apply the algorithm for the rest of the time series, we see a picture like below. This is the dimension-\(x\) of the Lorenz attractor. Red signal is the forecasted one, and the blue signal below is the error given for each prediction. Not bad, right? :)
If we apply the algorithm for the rest of the time series, we see a picture like below. This is the dimension-\(x\) of the Lorenz attractor. Red signal is the forecasted one, and the blue signal below is the error given for each prediction. Not bad, right? :)
 There goes the link to the Github project.
There goes the link to the Github project.
[1] Bradley E, Kantz H. Nonlinear time-series analysis revisited. Chaos: An Interdisciplinary Journal of Nonlinear Science. 2015 Sep;25(9):097610.
[2] Sugihara G. Nonlinear forecasting for the classification of natural time series. Phil. Trans. R. Soc. Lond. A. 1994 Sep 15;348(1688):477-95.
[3] Lorenz EN. Atmospheric predictability as revealed by naturally occurring analogues. Journal of the Atmospheric sciences. 1969 Jul;26(4):636-46.
[4] Packard NH, Crutchfield JP, Farmer JD, Shaw RS. Geometry from a time series. Physical review letters. 1980 Sep 1;45(9):712.
[5] Eckmann JP, Ruelle D. Ergodic theory of chaos and strange attractors. The Theory of Chaotic Attractors 1985 (pp. 273-312). Springer, New York, NY.
[6] Zeng, Wei and Razib, Muhammad and Shahid, Abdur Bin. Diffeomorphism Spline. Axioms. 2015.
[7] Takens F. Detecting strange attractors in turbulence. InDynamical systems and turbulence, Warwick 1980 1981 (pp. 366-381). Springer, Berlin, Heidelberg.
[8] Sauer T, Yorke JA, Casdagli M. Embedology. Journal of statistical Physics. 1991 Nov 1;65(3-4):579-616.
[9] Pecora LM, Moniz L, Nichols J, Carroll TL. A unified approach to attractor reconstruction. Chaos: An Interdisciplinary Journal of Nonlinear Science. 2007 Mar;17(1):013110.
[10] Vlachos I, Kugiumtzis D. State space reconstruction for multivariate time series prediction. arXiv preprint arXiv:0809.2220. 2008 Sep 12.
[11] Kennel MB, Brown R, Abarbanel HD. Determining embedding dimension for phase-space reconstruction using a geometrical construction. Physical review A. 1992 Mar 1;45(6):3403.
[12] Casdagli M. Chaos and deterministic versus stochastic non-linear modelling. Journal of the Royal Statistical Society. Series B (Methodological). 1992 Jan 1:303-28.
There are many studies concerned with this fundamental issue of distinguishing chaos from noise, which can be a real challenge. Both chaotic and random signals exhibit irregular temporal fluctuations, both have a fast-decaying auto-correlation function, and both are hard to forecast. But the nature of their dynamics are quite different : chaos is deterministic, noise is not [1]. That's the reason why the question of chaos versus noise is so attractive : low-dimensional nonlinear determinism may allow short-term predictability [2]. In a deterministic system, short-term futures of two almost-identical states should be similar, whereas in a pure noise process, that is improbable [1].
This idea of "future of my peers is my future" was first proposed by Lorenz in 1969 to predict the atmosphere [3]. He introduced the "Lorenz Method of Analogues", which searches the known state-space trajectory (in this case the state variables are temperature, pressure, distribution of wind, water vapor, etc.) for the nearest neighbor of a given state, and takes that neighbor’s forward path as the forecast. Essentially, it is a nearest-neighbor prediction.
Lorenz used all the variables, i.e., the full system state space - at least the full one he could think of. Say he could only measure temperature, but he also knew that the state space has a bigger dimension - more variables - than only one. This is generally the case when we observe natural phenomena. Governing equations and the state variables are rarely known, and have access to only a few scalar measurements observed from the system. What can be done with that? It simply depends on how much information is contained in the dynamics of the variable "temperature". It can be the case that one observed variable contains all the dynamical information of the system, and such systems are called inseparable.
The concept of inseparability deserves a bit of attention, also because of its role in quantum mechanics (It is indeed what Einstein called "spukhaft Fernwirkung" or "spooky action at a distance"). In terms of dynamical systems, inseparability means that the variables of a system cannot be computed separately. As an example, say you have a an ODE system in the following form \begin{align} \frac{dx}{dy} = g(x)h(y). \end{align} As long as \(h(y) \neq 0\), terms can be rearranged such that \begin{align} \frac{1}{h(y)}dy - g(x)dx = 0. \end{align} One can compute the two integrals \(\int \frac{1}{h(y)}dy\) and \(\int g(x)dx\) separately, and solve the equation. Good old separation of variables. On the other hand, imagine you have the following form of ODEs \begin{align} \frac{dx}{dy} = g(x)+yh(x). \end{align} This simply cannot be solved by using separation of variables, since you will have \(dx\) terms associated with \(y\), and vice versa. Hence the system is inseparable. This is actually useful for prediction purposes, because it tells us that if the atmosphere is an inseparable nonlinear system, then one of the observed variables - in this case temperature - can contain all the dynamical information about the atmosphere itself. One cannot compute the atmosphere without the temperature, and the temperature without the atmosphere.
The next question is how to squeeze out this information from the scalar time series we observed : How to reconstruct the state vector of the dynamical system from a single observed variable.
Solution to this problem was first proposed by Norman Packard and colleagues in 1979, and later was formalized by Floris Takens. Packard asked the same question in the context of fluid dynamics : How can we discern the nature of the strange attractor underlying turbulence from observing the actual fluid flow? [4]
The heuristic idea behind the reconstruction method is the following : to specify the state of an \(m\) dimensional system at a given time, you need \(m\) independent quantities. As an example, say you have a 3-dimensional system \begin{align} \mathbf{s}_{t} = \Big(x_{t},\,y_{t},\,z_{t}\Big), \end{align} and you aim to reconstruct an equivalent of \(\mathbf{s}_{t}\) (this means certain characteristics of \(\mathbf{s}_{t}\) should remain intact) by just observing \begin{align} x_{t} = x(\omega),\,\,\omega\in[0,t]. \end{align} Since you only have \(x(t)\), there is not much to do but try to generate several different scalar series from it. Simplest way to do it is to delay the same signal in time [5], and generate 3 different time series such that the reconstructed state of the system is defined as \begin{align} \mathbf{x}_{t} = \Big(x_{t},\,x_{t-\tau},\,x_{t-2\tau}\Big). \end{align} Here, the term independent in "\(m\) dimensional system \(\rightarrow\) \(m\) independent quantities" relation gains some practical meaning. Since you are delaying the very same signal, how can you minimize the redundancy between the delayed signals while having them still casually related (not completely irrelevant)? At the end, you don't want all dimensions to be the same, but you also don't want them to be so irrelevant such that there is no meaning in putting them together.
As you can imagine, there has been many techniques proposed to find the optimal delay time \(\tau\) using different measures (correlation, mutual information, etc.). I will not go into the details of that discussion, and simply move on assuming that we have a \(\tau\) that is good enough.
Back to the reconstruction problem. What Packard and colleagues conjectured in [4] was the following
To specify the state of a three-dimensional system at any given time, the measurement of any three independent quantities should be sufficient [...]. We conjecture that any such sets of \(m\) independent quantities which uniquely and smoothly label the states of the attractor are diffeomorphically equivalent.In English, this means that this reconstruction have the same topology as the original attractor, and the mapping is
1) One-to-one and onto (every point on \(\mathbf{s}_{t}\) paired with exactly one point on \(\mathbf{x}_{t}\) and vice versa).
2) Invertible.
3) Differentiable with also its inverse being differentiable (smooth).
This operation of mapping the scalar time series on an \(m\) dimensional space is called embedding, with embedding dimension being \(m\).
Although the word "diffeomorphism" sounds a bit scary, it is actually quite common in image processing. As an example, a fish eye filter can be thought as a mapping from a disc to a sphere, is a diffeomorphism. You can see a cute example [6] below :)
Takens' Embedding Theorem
After Packard proposed this conjecture, Takens [7] and later Sauer et al. [8] independently put this idea on a mathematically sound footing by showing that given any time delay \(\tau\) and a large enough \(m\), nearly all delay reconstructions are appropriately diffeomorphic to the original state space vector [9]. I will come back to the what "large enough \(m\)" means very soon, but lets write down the theorem with a proper notation first.Reconstruction of the State Space
Say a dynamical system generates a trajectory in a \(D\) dimensional manifold \(\Gamma\). For discrete time, the dynamical system is defined by the \(D\)-dimensional map \(\mathbf{F}\,:\,\Gamma \mapsto\,\Gamma\) as
\begin{align}
\mathbf{s}_{n+1} = \mathbf{F}(\mathbf{s}_{n}),\,\,\, n\in \mathbb{N},
\end{align}
where \(\mathbf{s}_{n} \in \Gamma \) is the state vector at time step \(n\). The observed scalar time series \(\{x_{n}\}_{n=1}^{N}\) of length \(N\) is the projection of the trajectory \(\{\mathbf{s}_{n}\}_{n=1}^{N}\) given by a measurement function \(h\,:\,\Gamma \mapsto \mathbb{R}\), as \(x_{n} = h(\mathbf{s}_{n})\).
According to Takens' Embedding Theorem, a trajectory formed by the time-delayed components from the time series \(x_{n}\) as \begin{align} \mathbf{x}_{n} = \Big({x}_{n},\,{x}_{n-\tau},\dots,\,{x}_{n-(m-1)\tau} \Big) \end{align} is an one-to-one mapping of the original trajectory of \(\mathbf{s}_{n}\) provided that m is large enough. Given that the dynamical system evolves to an attractor \(A \subset \Gamma \), the reconstructed attractor \(\overset{\sim}{A}\) through the use of time-delay vectors is topologically equivalent to \(A\). The embedding process can be visualized with the following graph [10] \[ \begin{array}{ccc} \mathbf{s}_{n} \in A \subset \Gamma & \xmapsto[]{\mathbf{F}} & \mathbf{s}_{n+1} \in A \subset \Gamma \\ \downarrow h & &\downarrow h \\ x_{n} \in \mathbb{R} & & x_{n+1} \in \mathbb{R} \\ \downarrow e & &\downarrow e \\ \mathbf{x}_{n} \in \overset{\sim}{A} \subset \mathbb{R}^{m} & \xmapsto[]{\mathbf{G}} & \mathbf{x}_{n+1} \in \overset{\sim}{A} \subset \mathbb{R}^{m} \end{array} \] where \(e\) is the embedding procedure creating the delay vectors, and \(G\) is the reconstructed dynamical system on \(\overset{\sim}{A}\). \(G\) preserves properties of the unknown \(F\) on the unknown attractor \(A\) that do not change under smooth coordinate transformations.
Let's check if that really works. Below you see a reconstruction of the Lorenz System using time-delay vectors of each dimension \(x_{t}\), \(y_{t}\), and \(z_{t}\). The colored points have the same index \(n\) to demonstrate the one-to-one and onto mapping property of the embedding.
Going back to the "large enough \(m\)" question : basically what we are doing by this embedding is projecting the time-delayed versions of the original time series on different axis of a higher dimensional space. Our aim is to preserve the properties of \(F\) in the reconstructed \(G\). Apart from the topological properties specific to \(F\), what is the fundamental property of any deterministic dynamical system? Trajectories cannot cross. A deterministic dynamical system's time evolution is determined entirely by its current location in the phase space. Meaning that if you're a given point in phase space, the next place you go is uniquely determined. Two trajectories that meet at the same point in the phase space are completely physically identical at that point, so they can't evolve in two different ways from identical initial conditions.
This gives us the condition of what the minimum embedding dimension should be : no crossing of trajectories. How can we check that? Kennel and colleagues proposed a practical way to do it in [11], which they called "The Method of False Neighbors". I really like the distinction he makes between a mathematician and physicist in the context of this problem. He says,
The general topological result of Mane and Takens states that when the attractor has dimension \(D\), all self-crossings of the orbit will be eliminated when one chooses \(m>2D\). These self-crossings of the orbit are a result of the projection, and the embedding process seeks to undo that. The Mane and Takens result is only a sufficient condition as can be noted by recalling that the familiar Lorenz attractor, \(D=2.06\), can be embedded by the time-delay method in \(m=3\). This is in contrast to the theorem, which only informs us that \(m=5\) will surely do the job. The open question is, given a scalar time series, what is the appropriate value for the minimum embedding dimension \(m_{E}\)? From the viewpoint of the mathematics of the embedding process it does not matter whether one uses the minimum embedding dimension \(m_{E}\) or any \(m \geq m_{E}\), since once the attractor is unfolded, the theorem's work is done. For a physicist the story is quite different. Working in any dimension larger than the minimum required by the data leads to excessive computation.So you can see that he is concerned about the practical outcomes of picking an unnecessarily large embedding dimension by using the usual method proposed by Takens. He also mentions the Lorenz attractor, which we unfolded by embedding in \(3\) dimensions just above. On the contrary, Takens theorem tells us that we should have used at least \(5\) dimensions to unfold it.
The Method of False Neighbors
What should be the practical reasoning for picking an embedding dimension then? Recall the "Lorenz Method of Analogues", which said the future of the nearest neighbors is the future of the current state. If neighbors of a current state depends on the embedding dimension, then it is a problem. For the idea of nearest-neighbor prediction to work, any dimension \(m \geq m_{E}\) should give similar neighbors. Otherwise, we are viewing the attractor in a too small embedding space.
A quick visual demonstration can be useful. In the figure below, you see the embedding of the Hénon map for \(m=2\) (top) and \(m=1\) (bottom). For \(m=1\), all three points - red, blue, and the green one - seem like they are neighbors. When the embedding dimension is increased by one, \(m=2\), then we see that the red point is actually a false neighbor. You can try to embed the system also for \(m=3\), and see that the blue and the green points stay neighbors although the red one is still false. We conclude that in this case \(m=2\) is sufficient to unfold the attractor.

This is the basic idea of "The Method of False Neighbors". Of course, a visual demonstration like above is not possible in most cases, so one needs to come up with an algorithmic way to find \(m\). Similar to the problem of determining the optimal \(\tau\), determining the minimum \(m\) is yet another question. Again, I will assume that we can find the minimum \(m\) using algorithms proposed in the literature, and skip that discussion for now. Using all this information, we can finally move to the problem of predicting a scalar time series.
Forecasting
The algorithm I will discuss here is adapted from the work of Martin Casdagli [12]. Honestly, when I first came across this algorithm, I didn't fully understand how - and why - it worked, and this bugged me almost for a full year. Time to time I went back to the problem, even coded it, but because of my lack of knowledge on Takens theorem - or in general, Topology - I had a hard time grasping the fundamental idea. Hopefully now, I think I understand it to the lowest extent technically possible to talk about it :)The problem is the following : We observed the scalar time series \(x_{n} = \Big(x[n],x[n-1],\dots,x[1]\Big)\), and we want to predict the next value of it in the future, \(x[n+1]\). It is likely that the data is coming from a higher dimensional system (observing the results of a natural complex phenomena, for example). We ignore any kind of noise - both system and observational - for the time being.
We can use the method of analogues proposed by Lorenz, but we don't have state vectors, we have scalars. That's where the method of analogues meet Takens' theorem. We can embed the time series, then find neighbors, and do the prediction. In other words, what we want to do is the green path in the diagram below.
Thanks to Takens, we know that the blue path is possible (recall all the properties about embedding being one-to-one and invertible, etc.). But we don't need to find \(G\) and invert the embedding, because other dimensions are also coming from the same scalar time series anyway. Predicting \(x_{n+1} = \Big(x[n+1],x[n],\dots,x[2]\Big)\) is not necessary for the sake of predicting \(x[n+1]\), because we already have the rest of the signal : \(\Big(x[n],\dots,x[2]\Big)\). So instead of taking the detour, we will take the red path, and apply the method of analogues when taking the turn.
Mathematically speaking, we will try to find the map \(g^{T} : \mathbb{R}^{m} \rightarrow \mathbb{R}\) such that \begin{align} x[n+T] &= g^{T}\Big(\mathbf{x}_{n}\Big), \\ &= g^{T}\Big({x}_{n},\,{x}_{n-\tau},\dots,\,{x}_{n-(m-1)\tau} \Big), \end{align} for \(T=1\), where \(g^{T}\) is assumed to be in the form of \begin{align} x[n+T] = \alpha_{0} + \sum_{k=1}^{m} \alpha_{k}x[n-(k-1)\tau], \end{align} which is simply an autoregressive model.
To sum it up, forecasting works as follows,
1) Find the nearest neighbors (NNs) of the embedded state \(x_{n}\).
2) Estimate the regression coefficients by using the future values of the NNs, which are already in the scalar time series (do some linear regression to get the \(\alpha_{k}\) values).
3) Use these coefficients for \(g^{T}(\mathbf{x}_{n})\) to forecast the first element of the future state \(x[n+T]\).
The beautiful part is that by using a sufficiently large embedding dimension, we can be sure that the neighbors we are using for the method of analogues are true neighbors. That is why the sufficient embedding dimension was a practical concern for Kennel.
The pseudocode of the whole algorithm proposed in [12] is below, and the link to the GitHub project is at the end of the post.
1 Divide the time series into two separate sets; a fitting set
\(x[0],\dots,x[N_{f}-1]\) and a testing set \(x[N_{f}],\dots,x[N_{f}+N_{t}-1]\).
2 Pick an embedding dimension \(m\), a delay time \(\tau\), and a
forecasting time \(T\).
3 for \(i\) \(\leftarrow\) \(N_{f}-1\) to \(N_{f}+N_{t}-T-1\) do
4 Construct the delay vector \(\mathbf{x}_{i} = (x[i],\,x[i-\tau],\dots,x[i-(m-1)\tau])\)
5 for \(j\) \(\leftarrow\) \((m-1)\tau\) to \(N_{f}-T-1\) do
6 Compute distances \(d_{ij}=|\mathbf{x}_{i}-\mathbf{x}_{j}|\)
7 end for
8 Order vectors depending on distances : \( l < k \) if \(d_{ij_l} < d_{ij_k}\).
9 Choose the first \(N\) nearest neighbors, pad with \(1\)s for
regression \(\mathbf{X} = \Big(1\,\,\mathbf{x}_{j_0}; \,1\,\,\mathbf{x}_{j_1};\dots;\,1\,\,\mathbf{x}_{j_{(N-1)}}\Big)\).
10 Take the corresponding future values
\(\mathbf{y} = \Big(x_{j_0+T};\,x_{j_1+T};\,\dots;\,x_{j_{(N-1)}+T}\Big)\).
11 Calculate coefficients via linear regression \(\boldsymbol{\alpha} = (\mathbf{X}^{\top}\mathbf{X})^{-1}\mathbf{X}^{\top}\mathbf{y}\).
12 Do the forecasting \(\hat{x}[i+T] = \Big(1\,\,\mathbf{x}_{i}\Big)\,\mathbf{\alpha}\).
13 end for
2
3
4
5
6
7
8
9
10
11
12
13
Some Cool Plots
I love plotting so here we go :) Below, you see the demonstration of the forecasting algorithm on the reconstructed Lorenz attractor. The black dot is the current state of the system, \(x_{t}\), embedded by using time-delay vectors where \(m=3\). The gray point is the real value of \(x_{t+T}\), current state \(T\) steps ahead in the future. The greenish / yellowish points are the nearest neighbors of the black dot, which are used for the approximation of the autoregressive model coefficients (color gets lighter as the distance to \(x_{t}\) gets bigger). Finally, the red circle is the predicted value \(\hat{x}_{t+T}\), projected back on the reconstructed attractor.
References
[1] Bradley E, Kantz H. Nonlinear time-series analysis revisited. Chaos: An Interdisciplinary Journal of Nonlinear Science. 2015 Sep;25(9):097610.[2] Sugihara G. Nonlinear forecasting for the classification of natural time series. Phil. Trans. R. Soc. Lond. A. 1994 Sep 15;348(1688):477-95.
[3] Lorenz EN. Atmospheric predictability as revealed by naturally occurring analogues. Journal of the Atmospheric sciences. 1969 Jul;26(4):636-46.
[4] Packard NH, Crutchfield JP, Farmer JD, Shaw RS. Geometry from a time series. Physical review letters. 1980 Sep 1;45(9):712.
[5] Eckmann JP, Ruelle D. Ergodic theory of chaos and strange attractors. The Theory of Chaotic Attractors 1985 (pp. 273-312). Springer, New York, NY.
[6] Zeng, Wei and Razib, Muhammad and Shahid, Abdur Bin. Diffeomorphism Spline. Axioms. 2015.
[7] Takens F. Detecting strange attractors in turbulence. InDynamical systems and turbulence, Warwick 1980 1981 (pp. 366-381). Springer, Berlin, Heidelberg.
[8] Sauer T, Yorke JA, Casdagli M. Embedology. Journal of statistical Physics. 1991 Nov 1;65(3-4):579-616.
[9] Pecora LM, Moniz L, Nichols J, Carroll TL. A unified approach to attractor reconstruction. Chaos: An Interdisciplinary Journal of Nonlinear Science. 2007 Mar;17(1):013110.
[10] Vlachos I, Kugiumtzis D. State space reconstruction for multivariate time series prediction. arXiv preprint arXiv:0809.2220. 2008 Sep 12.
[11] Kennel MB, Brown R, Abarbanel HD. Determining embedding dimension for phase-space reconstruction using a geometrical construction. Physical review A. 1992 Mar 1;45(6):3403.
[12] Casdagli M. Chaos and deterministic versus stochastic non-linear modelling. Journal of the Royal Statistical Society. Series B (Methodological). 1992 Jan 1:303-28.